

Hi everyone!
It is Springtime and the Science Scribbler Team is back with updates to our Key2Cat project. Since its launch, over 2,100 volunteers have contributed to our project by picking and classifying nanoparticles from the most difficult images. The entire team is deeply grateful for your humongous support, and we are excited to announce that we are now approaching the very last steps towards completion!
Some of you may know that the last stage of our project – the Pd/C nanoparticle cleaner workflow – has been online for the longest. This is mainly due to the sheer number of nanoparticles that need to be classified. However, there are now less than 180,000 classifications left before we complete the dataset!
But why is the classification counter only showing us ~ 30 % then, you ask? This is rooted in the way Zooniverse counts completed subjects: Only when 5 individuals classify a specific image, is it considered a ‘completed subject’ and reflected in the statistics. This is also the reason why the completion percentage did not move from 0 % in the beginning, despite the fact that thousands of you have contributed to this workflow.
However, this also means THAT THE PROGRESS BAR INCREASES FASTER WITH AN INCREASING NUMBER OF CLASSIFICATIONS!
BLOSSOMING CLASSIFICATIONS

With that in mind, let us have a more detailed look into your classifications. Our last blog post has shown you how we can integrate your picks and classifications into the HDBSCAN machine learning algorithm to get highly precise nanoparticle classification map in the original, large electron microscopy image of the Au/Ge system. In the case of Pd/C, the classification is still ongoing. Let’s consider the following original electron microscope image of Pd/C with all of your picks reconstructed:
Numerous picks (green circles in Figure 1b) were shown to you for classification. In the spirit of spring, this is how each of the circles are blossoming to become full classes (or flowers if you would like) with every single classification that you contribute:
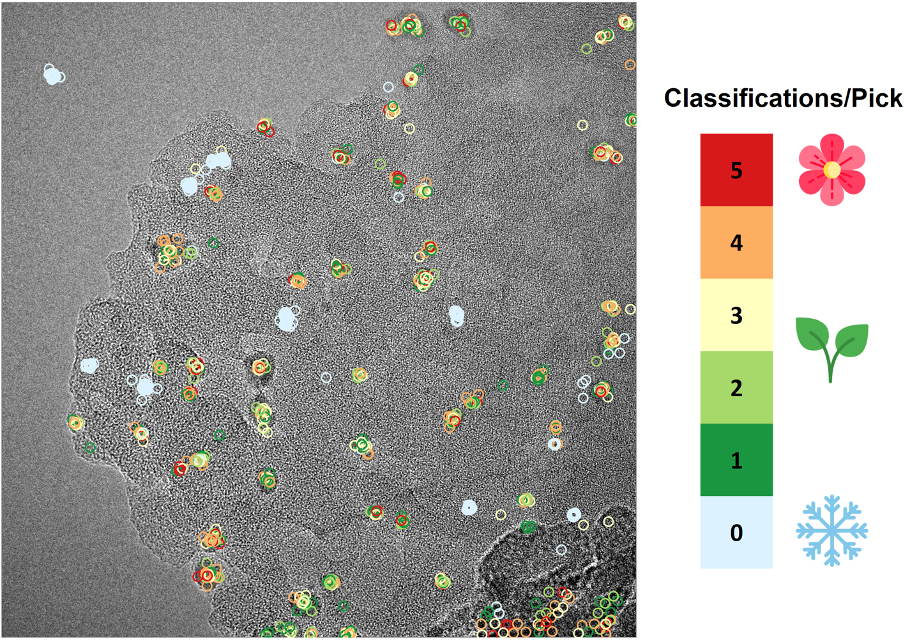
Now we can see how individual picks are classified: Totally random! This does not only hold true for this image, but for our entire Pd/C dataset. While ice-blue circle show subjects that have yet not been under assessment by our citizen scientists, red ones correspond to completed subjects. It also gives us a feeling of how many classifications are required for a single image to be completed – hence this gigantic number of subjects (117,291) and number of classifications.
GOING FOR THE LAST STEPS
How can we get the last 180,000 classifications done? Let’s do some quick analysis of the user sessions in Pd/C classification workflow:
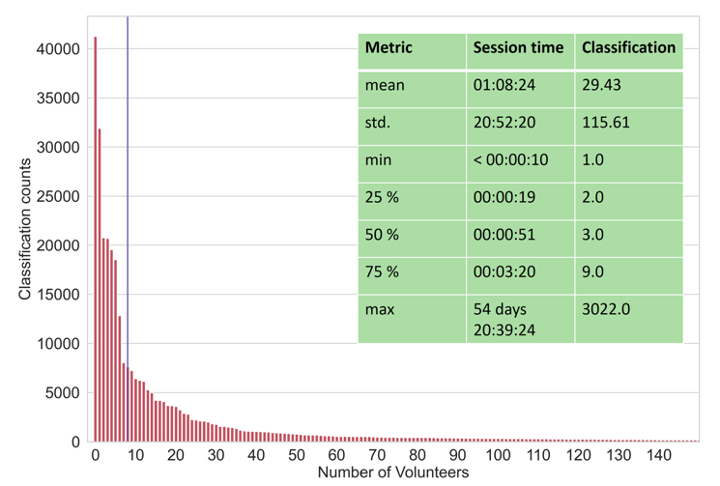
Having a look at the mean session time of a user and classifications done per session, we can deliver great news: nearly 30 classifications are done in a single session which takes about an hour. However, looking a bit more closely, we can see that the data is not evenly distributed, as the standard deviation takes a value of nearly 21 hours. Indeed, looking at the 50th percentile, the session time clocks in at the shorter duration of 51 seconds at 3 classifications.
In addition, we can consider the number of classifications done per individual user and in all honesty, we have been completely staggered: We have individual citizen scientists who contributed over 20,000 classifications for this workflow!
Without mentioning the top 10 users explicitly, we wanted to highlight a SPECIAL THANK YOU from the entire team to this absolute marvellous effort. At the same time we would like to thank all citizen scientists who are interested in our project and decided to dedicate their time to classify some particles of ours. These make up a huge proportion of our data, without which none of this would be possible. In fact, the power of citizen science is in the crowd – no single contributor could complete the project alone, because we need multiple people to look at each image, so every contribution is extremely valuable to us!
However, this data shows us that we need to ask you for a favour: If you contribute to our project, please make sure to leave a couple of classifications and to spend at least 3-4 min classifying. That way, the residual 180,000 classifications will be done in no time!
That’s it for now – we will hopefully be back soon once the data collection stage has finished and when we are ready to summarise our findings. Have a lovely springtime!
Kevin & Tricia

That’s cool project. I read them very well job